Data Distribution Patterns: Fanout-on-Read vs. Fanout-on-Write
On This Page
Executive Summary / TL;DR
An engineering playbook comparing fanout-on-read and fanout-on-write, detailing latency, storage, and scalability trade‑offs for large‑scale distributed systems.
Key Takeaways
- Prioritize fanout-on-read when write throughput exceeds 10k ops/sec to minimize storage overhead.
- Adopt fanout-on-write for sub‑100 ms read latency targets in high‑read traffic services.
- Limit fanout-on-read query fan‑out to ≤5 services to keep read latency under 200 ms.
- Allocate additional storage budget of 20 % when implementing fanout-on-write replication.
- Design fanout logic using idempotent microservice calls to reduce code complexity and bugs.
In the realm of large-scale system design, one of the critical decisions architects face is how to handle data distribution effectively. Two prominent approaches to data distribution are fanout-on-read vs. fanout-on-write. Each approach offers its own set of advantages and challenges, catering to different use cases and system requirements. In this article, we'll delve into these two data distribution patterns, examining their characteristics, pros, cons, and suitable use cases.

Understanding Fanout-on-Read
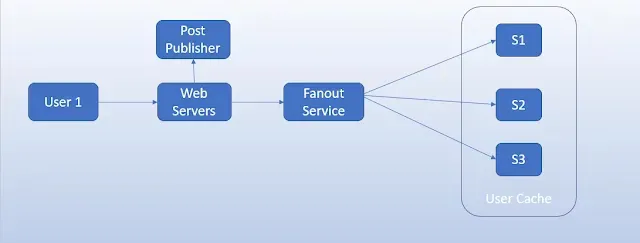
Fanout-on-read, as the name suggests, involves distributing data at the time of a read operation. In this approach, data isn't pre-computed or pre-distributed; instead, when a read request is made, the system dynamically fans out the query to multiple sources or services to retrieve the required information.
Pros of Fanout-on-Read:
- Low Initial Overhead: Since data isn't pre-processed or replicated beforehand, there's minimal upfront work required during write operations.
- Flexibility: Fanout-on-read offers flexibility as computations and aggregations are done at the time of reading. This makes it easier to modify the fanout logic, adapting to changing data structures or sources.
- Storage Efficiency: There's no need for additional storage to pre-compute or replicate data, resulting in efficient use of storage resources.
Cons of Fanout-on-Read:
- High Read Latency: Since the system performs computations and aggregations during read operations, users may experience longer wait times, especially for complex queries.
- Potential Complexity: Implementing complex fanout logic may lead to increased code complexity, potentially resulting in bugs or maintenance challenges.
- Scalability Concerns: As the volume of read operations increases, the system may face challenges in scaling to handle the load efficiently.
Exploring Fanout-on-Write
In contrast, fanout-on-write involves pre-computing, pre-processing, or replicating data at the time of a write operation. This approach ensures that the system has data readily available for reading, reducing the complexity and latency of read operations.
Pros of Fanout-on-Write:
- Fast Reads: With data pre-computed or replicated, read operations are generally much quicker, leading to reduced latency.
- Reduced Read-Time Complexity: Since data is structured for quick retrieval, the system doesn't need to perform complex computations during read operations, resulting in faster response times.
- Scalability: Fanout-on-write systems can efficiently handle increased read operations as data is already structured for quick retrieval, enhancing scalability.
Cons of Fanout-on-Write:
- Higher Write Overhead: Pre-computing or replicating data can result in higher write-time overhead, potentially slowing down write operations.
- Storage Costs: Storing pre-computed or replicated data may require additional storage resources, leading to increased storage costs.
- Inflexibility: Changes to the data structure or distribution logic may require significant modifications, limiting flexibility.
Choosing the Right Approach
The choice between fanout-on-read and fanout-on-write depends on various factors, including the specific requirements of the system, read and write volumes, latency considerations, and scalability needs.
Use Cases for Fanout-on-Read:
- Systems with high write activity but fewer reads.
- Applications where read latency isn't critical, and flexibility in data retrieval is essential.
- Distributed databases or systems requiring complex computations during read operations.
Use Cases for Fanout-on-Write:
- Systems with high read volume and low tolerance for read latency.
- Applications where fast data retrieval is crucial, such as content delivery networks (CDNs) or caching systems.
- Social media platforms or real-time analytics systems requiring quick access to frequently accessed data.
Fanout-on-read and fanout-on-write are valuable data distribution patterns in system design, each offering distinct advantages and challenges. Understanding the characteristics, pros, and cons of each approach is essential for architects and developers to make informed decisions based on the specific requirements of their systems. By carefully evaluating factors such as read and write volumes, latency constraints, and scalability needs, organizations can choose the most suitable data distribution pattern to optimize performance and efficiency in their large-scale systems.
Liked this insight?
Share it with your colleagues and network.
Frequently Asked Questions
What is fanout-on-read?
Fanout-on-read distributes data at read time, querying multiple sources. It enables flexible aggregation but can increase read latency.
What is fanout-on-write?
Fanout-on-write pre-computes data at write time, enabling fast reads. It reduces read complexity while adding write overhead and storage cost.
How to choose between fanout-on-read and fanout-on-write?
Choose based on read/write volume, latency tolerance, and scalability requirements. Evaluate traffic patterns and cost constraints before deciding.